I have been not-so-recently tasked with the job of putting together my
family's family tree. It has occurred to me that other people might want to
give the task a try, so here is my experience as a programmer.
First steps
The first important step was collecting my family
information. I did this the old-fashioned way,
sitting down with my mom and writing down in a spreadsheet
names and relations. We didn't go beyond "married to" and
"son/daughter of" because it was not important for us,
but you could extend this information with birthdays,
marriage dates, and so on.
The spreadsheet was good for collecting data fast, but
getting the graph done required better tools: like
all good programmers I'm lazy,
and I'm not going to sit down and hand-place over 100
nodes if I can avoid it.
I therefore turned to
Gramps,
an open-source software for Genealogical research. This
software offers a lot of functionality and may seem
daunting at times, but fear not: the software is clearly
done by people who understand the problem very well, and
it lets you record as much or as little information as you
want. My favorite example: you can add a person with no
name and no birth date, and the software will not even
complain. I think it also auto-fills a person's gender based on
their name.
Gramps has plenty of visualization options, and if you're not a software
developer you can use one of them and stop reading here.
Luckily I am a software developer, and un-luckily I couldn't find
any visualization that did what I wanted. I was looking for a
compact graph that I could fit in an A4 page, but all I
could generate in Gramps' GUI were trees with very generous
white space between nodes. This is in no way a point against
Gramps, by the way: no software package can be everything
for everyone, and I don't think I've ever had a graphic
design project that I didn't need to hand-tweak one way or
another. But one way or another, it was now time for massaging some data.
Tweaking the graph
After exporting the Gramps database to a CSV file, I decided to use
Graphviz for automatic node placement.
Graphviz is my go-to tool for drawing
complex graphs, and I knew it could get the job done, but first I would have
to convert my CSV file to Graphviz' DOT format.
So I wrote the following script, which generates a DOT version of the input file.
#!/usr/bin/python3
import csv
# Counter with my own internal IDs, for fake nodes
counter = 1000
# Maps people to their intermediate relation nodes
relation = dict()
# Maps between Gramps IDs and my own internal ones
old2new = dict()
print("digraph G {")
# This CSV file should contain the following columns:
# 1: Name, 2: Last name, 4: Father ID, 5: Mother ID, 6: Partner
# A default Gramps export should be already structured like this.
with open('gramps_database.csv') as csvfile:
datareader = csv.reader(csvfile)
for row in datareader:
id = row[0]
# By default, you are in a relation with yourself
# Useful for single parents
relation[id] = counter
counter += 1
name = row[1] + " " + row[2]
parents = None
partner = None
if row[4]:
father = row[4]
parents = relation[father]
if row[5]:
mother = row[5]
parents = relation[mother]
if row[6]:
partner = row[6]
if partner not in relation:
relation[partner] = relation[id]
else:
relation[id] = relation[partner]
# Note that we have all information we need for this person,
# we are not dependent on a future iteration.
# Therefore, we can print this section of the tree.
# First, the name
print("{}[label=\"{}\"];".format(id,name))
# Now, relations
if parents is not None:
print("{} -> {};".format(id, parents))
if partner is not None:
print("{} -> {} [dir=none];".format(id, relation[partner]))
print("}")
I then fed this output (tree.dot) to Graphviz. After playing with
different visualization options, I settled for the following options:
sfdp -Tpdf -Gsplines=true -Goverlap=false tree.dot -o tree_output.pdf
which ended up looking like this:
This is still not perfect, but it's 85% there and it's
something I can easily work with. I imported
this graph into Inkscape,
moved nodes around until they fit as tightly as I wanted, and added
some colors.
Border
One of my known weaknesses is that I'm very picky on the
graphic design of my projects: why stop at doing something
right, when you can do it right and good looking?
For this reason, I am constantly collecting pictures of
cool posters, certificates, book covers, t-shirts, and
pretty much everything that can be designed for print.
You never know when something might come useful as
inspiration!
Interesting enough, my collection of museum family trees
was not as helpful as I expected: while very nice to look
at, I found most trees difficult to understand, too simple,
or too much illustration and not enough content (most
artists are really invested into the "tree" metaphor).
What did help me, however, was my collection of
old-fashioned documents: the border of this tree is based
on a 1923 Share Certificate from the "Charlottenburger Wasser-
und Industriewerke AG", as seen in Berlin's
Museum in Alten Wasserwerk.
Using it as a template, I created a vector version in
Inkscape and placed it around my tree, which gives it a
nicer "feel" and leads us to this version (with names removed intentionally):

The space on the right was originally reserved for legends, references, and
whatever else, but so far I haven't come up with anything. And of course,
I also need some space for future family members.
Final steps
The final step was to share it with my family, which was
done with a combination of e-mail and telephone calls.
About once a month I get a list of corrections from family
members, which I do directly in Inkscape because at this
point it's faster. I still keep the Gramps database
updated, though, as I never know which future projects
might require it.
The final tree can be printed in A4, as desired, but I
wouldn't recommend anything smaller than A3. As a service
for my readers, and painfully aware of how difficult it is to find
good frames, you can download the empty template in
.SVG format following this link
to use in your own projects.
April 21: see the "Update" section at the end for a couple extra details.
A very common operation when programming is iterating over elements with a
nested loop: iterate over all entities in a collection and, for each element,
perform a second iteration.
A simple example in a bank setting would be a job
where, for each customer in our database, we want to sum the balance of each
individual operation that the user performed. In pseudocode, it could be
understood as:
for each customer in database:
customer_balance=0
for each operation in that user:
customer_balance = customer_balance + operation.value
# At this point, we have the balance for this one customer
Of all the things that Python does well, this is the one at which Python makes
it very easy for users to do it wrong. But for new users, it might not be
entirely clear why. In this article we'll explore what the right way is
and why, by following a simple experiment: we create an n-by-n list
of random values, measure how long it takes to sum all elements three
times, and display the average time in seconds to see which algorithm is the
fastest.
values = [[random.random() for _ in range(n)] for _ in range(n)]
We will try several algorithms for the sum, and see how they improve over
each other. Method 1 is the naive one, in which we implement a nested
for-loop using variables as indices:
for i in range(n):
for j in range(n):
acum += values[i][j]
This method takes 42.9 seconds for n=20000, which is very bad.
The main problem here is the use of the i and j variables. Python's dynamic
types and duck typing means that,
at every iteration, the interpreter needs to check...
- ... what the type of
i is
- ... what the type of
j is
- ... whether
values is a list
- ... whether
values[i][j] is a valid list entry, and what its type is
- ... what the type of
acum is
- ... whether
values[i][j] and acum can be summed and, if so, how -
summing two strings is different from summing two integers, which is also
different from summing an integer and a float.
All of these checks make Python easy to use, but it also makes it slow. If we
want to get a reasonable performance, we need to get rid of as many variables
as possible.
Method 2 still uses a nested loop, but now we got rid of the indices and
replaced them with
list comprehension
for row in values:
for cell in row:
acum += cell
This method takes 17.2 seconds, which is a lot better but still kind of bad.
We have reduced the number of type checks (from 4 to 3), we removed two
unnecesary objects (by getting rid of range), and acum += cell only needs
one type check. Given that we still need checking for cell and row,
we should consider getting rid of them too.
Method 3 and Method 4 are alternatives to using even less variables:
# Method 3
for i in range(n):
acum += sum(values[i])
# Method 4
for row in values:
acum += sum(row)
Method 3 takes 1.31 seconds, and Method 4 pushes it even further with
1.27 seconds. Once again, removing the i variable speed things up,
but it's the "sum" function where the performance gain comes from.
Method 5 replaces the first loop entirely with the map function.
acum = sum(map(lambda x: sum(x), values))
This doesn't really do much, but it's still good: at 1.30 seconds, it is
faster than Method 3 (although barely). We also don't have much code left to
optimize, which means it's time for the big guns.
NumPy is a Python library for scientific applications.
NumPy has a stronger type check (goodbye duck typing!), which makes it not
as easy to use as "regular" Python. In exchange, you get to extract a lot of
performance out of your hardware.
NumPy is not magic, though. Method 6 replaces the nested list values
defined above with a NumPy array, but uses it in a dumb way.
array_values = np.random.rand(n,n)
for i in range(n):
for j in range(n):
acum += array_values[i][j]
This method takes an astonishing 108 seconds, making it by far the worst
performing of all. But fear not! If we make it just slightly smarter, the
results will definitely pay off. Take a look at Method 7, which looks a lot
like Method 5:
acum = sum(sum(array_values))
This method takes 0.29 seconds, comfortably taking the first place. And
even then, Method 8 can do better with even less code:
acum = numpy.sum(array_values)
This brings the code down to 0.16 seconds, which is as good as it gets
without any esoteric optimizations.
As a baseline, I've also measured the same code in single-threaded C code.
Method 9 implements the naive method:
float **values;
// Initialization of 'values' skipped
for(i=0; i<n; i++)
{
for(j=0; j<n; j++)
{
acum += values[i][j];
}
}
Method 9 takes 0.9 seconds, which the compiler can optimize to 0.4 seconds
if we compile with the -O3 flag (listed in the results as Method 9b).
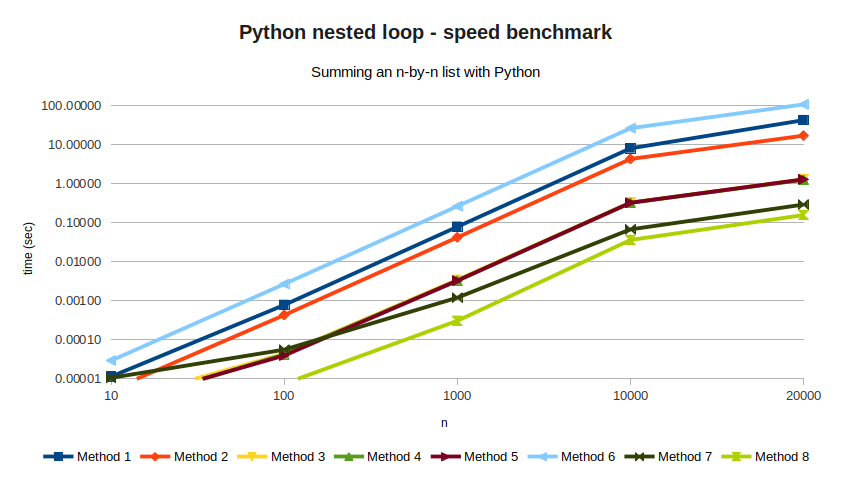
All of these results are listed in the following table, along with all the
values of n I've tried.
While results can jump a bit depending on circumstances (memory usage,
initialization, etc), I'd say they look fairly stable.
|
N=10 |
N=100 |
N=1000 |
N=10000 |
N=20000 |
| Method 1 |
0.00001 |
0.00078 |
0.07922 |
8.12818 |
42.96835 |
| Method 2 |
0.00001 |
0.00043 |
0.04230 |
4.34343 |
17.18522 |
| Method 3 |
0.00000 |
0.00004 |
0.00347 |
0.33048 |
1.30787 |
| Method 4 |
0.00000 |
0.00004 |
0.00329 |
0.32733 |
1.27049 |
| Method 5 |
0.00000 |
0.00004 |
0.00329 |
0.32677 |
1.30128 |
| Method 6 |
0.00003 |
0.00269 |
0.26630 |
26.61225 |
108.61357 |
| Method 7 |
0.00001 |
0.00006 |
0.00121 |
0.06803 |
0.29462 |
| Method 8 |
0.00001 |
0.00001 |
0.00031 |
0.03640 |
0.15836 |
| Method 9 |
0.00000 |
0.00011 |
0.00273 |
0.22410 |
0.89991 |
| Method 9b |
0.00000 |
0.00006 |
0.00169 |
0.09978 |
0.40069 |
Final thoughts
I honestly don't know how to convey to Python beginners what the right way
to do loops in Python is. With Python being beginner-friendly and Method 1
being the most natural way to write a loop, running into this problem is not
a matter of if, but when. And any discussion of Python that includes terms
like "type inference" is likely to go poorly with the crowd that needs it the
most.
I've also seen advice of the type "you have to do it like this because I say so
and I'm right" which is technically correct but still unconvincing.
Until I figure that out, I hope at least this short article will be useful
for intermediate programmers like me who stare at their blank screen and
wonder "two minutes to sum a simple array? There has to be a better way!".
Further reading
If you're a seasoned programmer,
Why Python is slow
answers the points presented here with a deep dive into what's going on under
the hood.
April 21 Update
A couple good points brought up by my friend Baco:
- The results between Methods 3, 4, and 5 are not really statistically
significant. I've measured them against each other and the best I got was a
marginal statistical difference between Methods 3 and 5, also known as "not worth it".
- Given that they are effectively the same, you should probably go for
Method 4, which is the easiest one to read out of those three.
- If you really want to benchmark Python, you should try something more
challenging than a simple sum. Matrix multiplication alone will give you
different times depending on whether you use liblapack3 or libopenblas
as a dependency. Feel free to give it a try!
If you are one of the lucky ones who didn't lose their jobs during the
current pandemic, you may also be one of the involuntary volunteers
taking part in the world's largest work-from-home
experiment.
There are several well-written guides on how different companies and
individuals do it. Software developers, who have been more or less
working from home for the last decade, have particularly good tips - if
you haven't yet read any of those guides, you can find a great thread
here with practical suggestions.
A less-talked point, and the topic of this article, is learning how to work
asynchronously with your team. That means: adapting your team's work style
not to rely on other people being available to you right now and, conversely,
not being "on call" for everyone all the time.
Synchronous work in the time of Cholera
In a regular, sane office setting the rules are clear: if my
colleagues need something from me, they can come by and ask.
If I'm busy they'll notice it, either because I'm with someone
or because my door is closed. But otherwise, answering their question
is literally my job, and when they ask me they get an immediate response.
This is a synchronous situation.
Remote work, on the other hand, does not lend itself well to this.
There can be a multitude of invisible reasons why I can't answer your
question right now: I could be on the phone,
stretching from hours sitting on my uncomfortable chair,
discussing lunch with my (also at home) partner, answering the
door, or multiple other situations that rarely happen in an office
setting and cannot be conveyed with a status icon.
For the synchronous worker, this situation is unacceptable. They will
send you an e-mail and five minutes later call to ask whether you
received it, or are the type of bosses
who film their employees to check whether they are
working.
Working synchronously while remote means being constantly dragged to
pointless calls ("hey, quick question!"). You dread leaving your desk
because you know there will be endless redundant notifications waiting
for you. And you end the day exhausted from switching tasks all the time.
A new paradigm
For a term that's so difficult to write, working asynchronously is
rather simple.
As part of a team, you need to embrace the idea that you cannot know
whether your coworkers are busy. For all you know, they are in a
different time zone and asleep. If you need someone's input you send them an e-mail
or an instant message (see below) and then... you move on to something
else. Your coworker will reply when it's convenient for them to do so.
And meetings must be agreed beforehand - no more calling out of the blue!
As an individual, you need to mute your notifications. I
recommend that you turn off all notifications except for when someone
"tags" you (that is, they write your username and you get notified)
for important topics that require your input. That doesn't mean
that you can go fishing during work hours - you will
still work, reply within a reasonable time frame, and be reachable
when time is of the essence. But you no longer have to reply right now.
Working like this presents many advantages. Important points
that would previously be discussed and forgotten are now
being communicated on a need-to-know basis via e-mail;
workers can easily step away from their desks knowing that nothing
critical will be missed, and will stop spending valuable time catching
up on notifications. And did you know that longer periods of
interruption-free work can save up to 40% of your productivity?
"Asynchronous" does not mean "hermit"
The most common argument against asynchronous work is that you lose
"human contact". And, while misguided, that's not a bad point:
loneliness is a big factor for lots of people right now, and talking
to their coworkers helps them cope in these uncertain times.
Luckily, there are solutions. A classic one is the "random" channel: a
virtual board where people are encouraged to post non-work-related
topics and discuss about their day. Another one is the "virtual office
lunch" where everyone gathers for an hour with their cameras on and just
talk.
And this is perfectly fine! I'm not saying "do not use Skype ever again".
But I hope you'll agree that there's a difference between "I'm in this
meeting because we planned it", "I'm in this meeting to waste some time
because it's fun", and "I'm in this meeting to waste my time because
someone thinks my time is worthless".
Working asynchronously is a team effort, where everyone needs to be on
the same page. But it's not hard to pull off, and it can make your
day more manageable. It might not be as helpful as toilet paper or
flour, but it's a good start nonetheless.
If you're a software developer, you know the rules: new year, new programming
language. For 2020 I chose Rust because it has a lot
going for it:
- Memory safe and high performance
- Designed for low-level tasks
- Backed by Mozilla, of which I'm a fan
- Named "most loved programming language" for the fourth year in a row by
the Stack Overflow Annual Survey
With all of these advantages in mind, I set to build something concrete: an
implementation of the Aho-Corasick algorithm.
This algorithm, at its most basic, builds a Trie
and then converts it into an automaton, with the final result being efficient
search of sub-strings (why? I hope I can write about why in the near future). It
also seemed like the type of problem you'd like to tackle with Rust:
implementing a Trie in C requires some liberal use of pointers, a task for which
I had expected Rust to be the right tool (memory safety!). And since I need to
run a lot of text through it, I need it to be as fast as possible.
So how did I fare? Two weeks into this project, Rust and I have... issues.
More specifically, I'm having real trouble figuring out what is Rust good
for.
Part I: Pointers and Strings are too complicated
Dealing with pointers is straight up painful, because allocating a piece of
memory and linking it to something else gets very difficult very fast. I
followed this book,
titled "Learn Rust With Entirely Too Many Linked Lists", and the opening alone
warns me that programming a linked list requires learning "the following
pointer types: &, &mut, Box, Rc, Arc, *const, and *mut". A Reddit thread,
on the other hand, suggests that a doubly-linked list is straightforward - all
you need to do is declare your type as Option<Weak<RefCell<Node<T>>>>.
Please note that neither Option, weak, nor RefCell are mentioned in
the previous implementation...
So, pointers are out as killer feature. If optimizing memory usage is not its
strong point, then maybe "regular" programming is? Could I do the rest of my
text handling with Rust? Sadly, dealing with Strings is not great either.
Sure, I get it, Unicode is weird. And I can understand why the difference
between characters and graphemes is there. But if the Rust developers thought
long and hard about this, why is "get me the first grapheme of this String"
so difficult? And why isn't such a common operation part of the standard
library?
For the record, this is a rhetorical question - the answer to "how do I
iterate over graphemes" (found
here) teaches us that...
- ... the developers don't want to commit to a specific method of doing this,
because Unicode is complicated and they don't want to have to support it
forever. If you want to do it, you have to pick an external library. But
it won't be part of the standard library anytime soon. At the same time, ...
- ... they don't want to "play favorites" with any specific library over
any other, meaning that no trace of a specific method is to be found in the
official documentation.
The result, then, is puzzling: the experts who designed the system don't want
to take care of it, the official doc won't tell you who is doing it right (or,
more critical, who is doing it wrong and should be avoided), and you are
essentially on your own.
Part II: the community
If we've learn anything from the String case, is that "just Google it" is a
valid development strategy when dealing with Rust.
This leads us inevitably to A sad day for Rust,
an event that took place earlier this year and highlighted how bad the Reddit
side of the community can be. To quote the previous article,
the Rust subreddit has ~87,000 subscribers (...) while Reddit is not official, and so not linked to by any official resources, it’s still a very large group of people, and so to suggest it’s "not the Rust community" in some way is both true and very not true.
So, why did I bring this up? Because
the Reddit thread I mentioned above
displays two hallmarks of the type of community I don't want to be a member of:
- the attitude of "it's very simple, all you need to create a new node is
self.last.as_ref().unwrap().borrow().next.as_ref().unwrap().clone()"
- the other attitude, where the highest rated comment is the one that
includes nice bits like "The only surprising thing about this
blog post is that even though it's 2018 and there are many Rust resources
available for beginners, people are still try to learn the language by
implementing a high-performance pointer chasing trie data-structure".
The fact that people may come to Rust because that's the type of
projects a systems language is supposedly good for seems to escape them.
If you're a beginner like me, now you know: there is a good community out
there. And it would be unfair for me to ignore that other forums, both
official and not, are much
more welcoming and understanding. But you need to double check.
Part III: minor annoyances
I really, really wish Rust would stop using new terms for concepts that
already exist: abstract methods are "traits", static methods are "associated
functions", "variables" are by default not-variable (and not to be confused with
constants), and any non-trivial data type is actually a struct with
implementation blocks.
And down to the very, very end of the scale, the trailing commas at the end
of match expressions, the 4-spaces indentation, and the official endorsement of
1TBS instead of K&R (namely, 4-spaces instead of Tabs) are just plain ugly.
Unlike Python, however, Rust does get extra points for allowing other,
less-wrong styles.
Part IV: not all is hopeless
Unlike previous rants, I want to point out something very important: I
want to like Rust. I'm sure it's very good at something, and I really,
really want to find what it is. It would be very sad if the answer to
"what is Rust good for?" ended up being "writing Rust compilers".
Now, the official
documentation (namely, the book)
closes with a tutorial on how to build a multi-threaded web server, which is
probably the key point: if Rust claims that error handling and memory safety
are its main priorities are true, then multi-threaded code could be the main
use case. So there's hope that everything will get easier once I manage to get
my strings inside my Trie, and iterating over Gb of text will be amazingly
easy.
I'll keep you updated.

{kind=link}