Building a Web App with nothing - Update
In my last post I mentioned a small webapp that I had built in an hour. This app was okay for what it was, but using it revealed that it needed a bit more love before it could be useful. And that's fine! After all, that was the whole point of making a quick mockup: to put it into the hand of users and see what their usage reveals about what's working and what isn't.
I have now written an updated version that you can see following this link. This new version has a couple small but important improvements:
- It adds a second tab where you can see all of your data. Useful for knowing which expenses you've already added and/or to make sure that your records are saved properly.
- It adds a button for clearing all data. I use this button not really to clear data, but rather to query the current date and time.
- It now shows messages showing that data was inserted properly. As it turns out, not even the developer trusts a program that stores data silently and gives no acknowledgement whatsoever.
I still have not fixed the CSV export error. That one will have to wait for a future version.
Building a Web App with nothing
I recently had to solve a problem that I already faced before: I need an app to keep track of my daily expenses, it has to run on my phone (so I can enter expenses on the run before I forget), and pretty much nothing else.
Last time I scratched this itch I built an Android app that did exactly that, and it worked fine for what I wanted. But time has passed, I have forgotten almost everything I knew about the Android SDK, and I wanted to get this version of the app done from scratch in one hour - for a single CRUD application that doesn't do the UD part, this seemed more than reasonable. So this time I decided to go for good old HTML and plain JavaScript.
Building the interface
I decided to build the app in pure HTML - the requirements of my project are modest, and I didn't want to deal with setting up a server anyway (more on this later). I did want my app to look good or at least okay but, while I do have some art delusions, I was never particularly good at web design. Therefore, I am a fan of fast web design frameworks that take care of that for me, and this project is not the exception. I am weirdly fond of Pure.css but for this project I wanted something new and therefore I settled for good old Bootstrap.
If you have never used either of these frameworks, the concept is simple: you include their code in the header of your HTML file, you copy the template that better fits the look you're going for, and that's it. In my case that means that my empty template looked like this:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Spendings</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.2/dist/css/bootstrap.min.css"
rel="stylesheet" crossorigin="anonymous"
integrity="sha384-T3c6CoIi6uLrA9TneNEoa7RxnatzjcDSCmG1MXxSR1GAsXEV/Dwwykc2MPK8M2HN">
</head>
<body>
<main>
<div class="my-4"></div>
<div class="container">
<h2>New expense</h2>
<form id="main_form">
<!-- Here comes the form fields -->
</form>
</div>
<div class="my-4"></div>
<div class="container">
<h2>Export expenses</h1>
<div class="row">
<div class="col text-center">
<form>
<button class="btn btn-primary" onClick="export_csv(); return false;";>
Export data to .CSV
</button>
</form>
</div>
</div>
</div>
</main>
<script src="https://cdn.jsdelivr.net/npm/bootstrap@5.3.2/dist/js/bootstrap.bundle.min.js"
integrity="sha384-C6RzsynM9kWDrMNeT87bh95OGNyZPhcTNXj1NW7RuBCsyN/o0jlpcV8Qyq46cDfL"
crossorigin="anonymous"></script>
</body>
</html>
Once this was up and running it was time to add form elements. In my case that meant fields for the following information:
- Expense: what it is that I actually bought.
- Amount: how much I paid for it.
- Date and Time: when did I buy it.
- Category: under which category it should be stored.
- Currency: in which currency is the expense - useful when I'm traveling back home.
- Recurrent: this is a checkbox that I use for expenses that I'll have to re-enter every other month such as rent. I have not yet implemented this functionality, but at least I can already enter this into the database.
- Two buttons: "Add expense" which would save this data, and "Export to CSV" to download the data saved so far.
The first three fields (expense, amount, and currency) look like this. Note that most of this code is a slightly edited version from the examples I copy-pasted from the official Bootstrap documentation:
<form id="main_form">
<div class="mb-3">
<label for="inputDesc" class="form-label" required>Description</label>
<input type="text" class="form-control" id="inputDesc" required>
<div class="invalid-feedback">Enter a description</div>
</div>
<div class="mb-3 row">
<div class="col-sm-8 input-group" style="width: 66%;">
<span class="input-group-text" id="descAmount">Amount</span>
<input type="number" step=".01" class="form-control" id="inputAmount" required>
<div class="invalid-feedback">Amount missing</div>
</div>
<div class="col-sm-4 input-group" style="width: 33%;">
<select class="form-select" id="inputCurrency">
<option selected value="eur">EUR</option>
<option value="usd">USD</option>
<option value="ars">ARS</option>
</select>
</div>
</div>
<!-- A lot of other fields -->
<div class="col text-center">
<button type="submit" class="btn btn-primary"
onClick="add_expense(event); return false;">
Add expense
</button>
</div>
And with that we are done with the interface.
Storing the data
Web browsers have become stupidly powerful in the last years, meaning that they not only include a full programming language (JavaScript) but also at least three mechanisms for saving data in your device: Cookies, Web Storage, and IndexedDB.
This mostly works for my project: having a database in my phone saves me the trouble of having to set a database in a server somewhere, but there's still a risk of data loss if and when I clean my device's cache. The solution, as you may have seen above, is an "Export to CSV" button that I can use to save my data manually once in a while - I could have chosen to e-mail myself the data instead, but that's the kind of feature I'll implement once I have a need for it.
We now need to delve into JavaScript. Most of the code I ended up using came from this tutorial, with the only exception that my code doesn't really need a primary index so instead of writing:
const objectStore = db.createObjectStore("name", { keyPath: "myKey" });
I went for:
const objectStore = db.createObjectStore("name", { autoincrement: true });
Once you have implemented most of that code, you are ready to insert data into
your database. In my case that's what the function add_expense is for and
it looks like this:
function add_expense(event)
{
// Validate the expense using the mechanism provided by Bootstrap
// See https://getbootstrap.com/docs/5.3/forms/validation/
form = document.getElementById("main_form");
form.classList.add('was-validated');
// These are the only two fields that need proper validation
expense = document.getElementById("inputDesc").value;
amount = document.getElementById("inputAmount").value;
if (expense.length == 0 || amount.length == 0)
{
event.preventDefault();
event.stopPropagation();
}
// Open a connection to the database
const transaction = db.transaction(["spendings"], "readwrite");
const objectStore = transaction.objectStore("spendings");
// Collect the data from the form into a single record
var data = {spending: expense,
date: document.getElementById("inputDate").value,
time: document.getElementById("inputTime").value,
category: document.getElementById("inputCateg").value,
amount: Number(amount),
currency: document.getElementById("inputCurrency").value,
recurrent: document.getElementById("checkRecurrent").checked};
// Store this record in the database
const request = objectStore.add(data)
transaction.onerror = (sub_event) => {
// This function is called if the insertion fails
console.log("Error in inserting record!");
alert("Could not save record");
// Displays a (currently hidden) error message
document.getElementById("warning_sign").style.display = 'block';
event.preventDefault();
event.stopPropagation();
}
transaction.oncomplete = (sub_event) => {
// This function is called if the insertion succeeds
console.log("Record added correctly");
// Ensures that the hidden error message remains hidden, or hides it
// if an insertion had previously failed and now succeeded
document.getElementById("warning_sign").style.display = 'none';
}
}
The function for creating the output CSV file is a simple combination of a call to retrieve every record in the database and this StackOverflow answer on how to generate a CSV file on the fly:
function export_csv(event)
{
// Open a connection to the database
const transaction = db.transaction(["spendings"], "readonly");
const objectStore = transaction.objectStore("spendings");
// Request all records
const request = objectStore.getAll();
transaction.oncomplete = (event) => {
// Header for the CSV file
let csvContent = "data:text/csv;charset=utf-8,";
csvContent += "date,time,expense,amount,category,currency,recurrent\r\n";
// Add every record in a comma-separated format.
// Can you spot how many bugs this code fragment has?
for (const row of request.result)
{
fields = [row['date'], row['time'], row['spending'],
row['amount'], row['category'],
row['currency'], row['recurrent']];
csvContent += fields.join(",") + "\r\n";
}
var encodedUri = encodeURI(csvContent);
window.open(encodedUri);
}
}
The above-mentioned code has a fatal bug: I am building a CSV file by simply concatenating fields together with a "," in between, and that's likely to break under many circumstances: if my description has a "," in it, if my locale uses "," as the decimal separator, if my description has a newline character for whatever reason, and many more. I could solve this by escaping/replacing every "," in the input fields with something else, but let's instead learn the proper lesson here: do not build CSVs by hand in production!
Conclusion
And just like that we are done. I set out to get it done in an hour, and I almost made it - I had some issues with the database not initializing properly, which I ended up solving by bumping up the database version and forcing the database to rebuild itself. The glorious final version can be found following this link. This app saves all of your data in your local device, meaning that you can start using it right now. But you don't have to take my word for it. If you don't trust some random dude with a blog you can always check the source code yourself and make sure that the version I'm linking to is the same I described above. Isn't open source code great?
I can imagine a couple reasons why one would want to develop an app like this. Perhaps you need a working prototype that you want to put in the hands of alpha testers right now. Perhaps you want an app that has to work in exactly one device. Or maybe you have to develop in an environment where all you have is a text editor, a web browser, and nothing more. This would be unacceptable for a professional environment, but sometimes the problems you're trying to solve are so simple that scaling up in resources and costs doesn't make sense. Or maybe you would like to go down to the basics once in a while and realize that not every app needs React, a web server, and a cloud deployment.
I didn't manage to do all I set up to do. Some upgrades that I'm planning to add gradually are:
- A fix to the CSV bug mentioned above.
- A message letting you know that you expense was inserted successfully.
- Implement the "Recuring expense" feature - I'm thinking of checking whenever you open the app whether the current month has any recurring expenses. If not, then the app asks you whether you want to insert them, one at a time (in case one of the expenses is no longer valid).
- A hint of what the conversion rate for that day is, in case I don't want to save "I bought this in US Dollars" but rather "I bought this in US Dollars and that converts to this many Euros".
And finally, I should point out that this project was originally conceived as a proof of concept for streaming and coding at the same time. I have video of the whole experience but, given that the camera died on me halfway, you will have to rely on my word when I say that you aren't missing much.
Write-only code
The compiler as we know it is generally attributed to Grace Hopper, who also popularized the notion of machine-independent programming languages and served as technical consultant in 1959 in the project that would become the COBOL programming language. The second part is not important for today's post, but not enough people know how awesome Grace Hopper was and that's unfair.
It's been at least 60 years since we moved from assembly-only code into what we now call "good software engineering practices". Sure, punching assembly code into perforated cards was a lot of fun, and you could always add comments with a pen, right there on the cardboard like well-educated cavemen and cavewomen (cavepeople?). Or, and hear me out, we could use a well-designed programming language instead with fancy features like comments, functions, modules, and even a type system if you're feeling fancy.
None of these things will make our code run faster. But I'm going to let
you into a tiny secret: the time programmers spend actually coding
pales in comparison to the time programmers spend thinking about what
their code should do. And that time is dwarfed by the time programmers
spend cursing other people who couldn't add a comment to save their
life, using variables named var and cramming lines of code as tightly
as possible because they think it's good for the environment.
The type of code that keeps other people from strangling you is what we call "good code". And we can't talk about "good code" without it's antithesis: "write-only" code. The term is used to describe languages whose syntax is, according to Wikipedia, "sufficiently dense and bizarre that any routine of significant size is too difficult to understand by other programmers and cannot be safely edited". Perl was heralded for a long time as the most popular "write-only" language, and it's hard to argue against it:
open my $fh, '<', $filename or die "error opening $filename: $!";
my $data = do { local $/; <$fh> };
This is not by far the worse when it comes to Perl, but it highlights the type of code you get when readability is put aside in favor of shorter, tighter code.
Some languages are more propense to this problem than others. The International Obfuscated C Code Contest is a prime example of the type of code that can be written when you really, really want to write something badly. And yet, I am willing to give C a pass (and even to Perl, sometimes) for a couple reasons:
- C was always supposed to be a thin layer on top of assembly, and was designed to run in computers with limited capabilities. It is a language for people who really, really need to save a couple CPU cycles, readability be damned.
- We do have good practices for writing C code. It is possible to write okay code in C, and it will run reasonably fast.
- All modern C compilers have to remain backwards compatible. While some edge cases tend to go away with newer releases, C wouldn't be C without its wildest, foot-meet-gun features, and old code still needs to work.
Modern programming languages, on the other hand, don't get such an easy pass: if they are allowed to have as many abstraction layers and RAM as they want, have no backwards compatibility to worry about, and are free to follow 60+ years of research in good practices, then it's unforgivable to introduce the type of features that lead to write-only code.
Which takes us to our first stop: Rust. Take a look at the following code:
let f = File::open("hello.txt");
let mut f = match f {
Ok(file) => file,
Err(e) => return Err(e),
};
This code is relatively simple to understand: the variable f contains
a file descriptor to the hello.txt file. The operation can either
succeed or fail. If it succeeded, you can read the file's contents by extracting
the file descriptor from Ok(file), and if it failed you can either do something
with the error e or further propagate Err(e). If you
have seen functional programming before, this concept may sound familiar
to you. But more important: this code makes sense even if you have
never programmed with Rust before.
But once we introduce the ? operator, all that clarity is thrown off
the window:
let mut f = File::open("hello.txt")?;
All the explicit error handling that we saw before is now hidden from you.
In order to save 3 lines of code, we have now put our error handling logic
behind an easy-to-overlook, hard-to-google ? symbol. It's literally there to
make the code easier to write, even if it makes it harder to read.
And let's not forget that the operator also facilitates the "hot potato" style of catching exceptions1, in which you simply... don't:
File::open("hello.txt")?.read_to_string(&mut s)?;
Python is perhaps the poster child of "readability over conciseness". The Zen of Python explicitly states, among others, that "readability counts" and that "sparser is better than dense". The Zen of Python is not only a great programming language design document, it is a great design document, period.
Which is why I'm still completely puzzled that both f-strings and the infamous walrus operator have made it into Python 3.6 and 3.8 respectively.
I can probably be convinced of adopting f-strings. At its core, they are designed to bring variables closer to where they are used, which makes sense:
"Hello, {}. You are {}.".format(name, age)
f"Hello, {name}. You are {age}."
This seems to me like a perfectly sane idea, although not one without
drawbacks. For instance, the fact that the f is both
important and easy to overlook. Or that there's no way to know what
the = here does:
some_string = "Test"
print(f"{some_string=}")
(for the record: it will print some_string='Test'). I also hate that
you can now mix variables, functions, and formatting in a way
that's almost designed to introduce subtle bugs:
print(f"Diameter {2 * r:.2f}")
But this all pales in comparison to the walrus operator, an operator designed to save one line of code2:
# Before
myvar = some_value
if my_var > 3:
print("my_var is larger than 3")
# After
if (myvar := some_value) > 3:
print("my_var is larger than 3)
And what an expensive line of code it was! In order to save one or two variables, you need a new operator that behaves unexpectedly if you forget parenthesis, has enough edge cases that even the official documentation brings them up, and led to an infamous dispute that ended up with Python's creator taking a "permanent vacation" from his role. As a bonus, it also opens the door to questions like this one, which is answered with (paraphrasing) "those two cases behave differently, but in ways you wouldn't notice".
I think software development is hard enough as it is. I cannot convince the Rust community that explicit error handling is a good thing, but I hope I can at least persuade you to really, really use these type of constructions only when they are the only alternative that makes sense.
Source code is not for machines - they are machines, and therefore they couldn't care less whether we use tabs, spaces, one operator, or ten. So let your code breath. Make the purpose of your code obvious. Life is too short to figure out whatever it is that the K programming language is trying to do.
Footnotes
Benchmarking Python loops
April 21: see the "Update" section at the end for a couple extra details.
A very common operation when programming is iterating over elements with a nested loop: iterate over all entities in a collection and, for each element, perform a second iteration. A simple example in a bank setting would be a job where, for each customer in our database, we want to sum the balance of each individual operation that the user performed. In pseudocode, it could be understood as:
for each customer in database:
customer_balance=0
for each operation in that user:
customer_balance = customer_balance + operation.value
# At this point, we have the balance for this one customer
Of all the things that Python does well, this is the one at which Python makes it very easy for users to do it wrong. But for new users, it might not be entirely clear why. In this article we'll explore what the right way is and why, by following a simple experiment: we create an n-by-n list of random values, measure how long it takes to sum all elements three times, and display the average time in seconds to see which algorithm is the fastest.
values = [[random.random() for _ in range(n)] for _ in range(n)]
We will try several algorithms for the sum, and see how they improve over each other. Method 1 is the naive one, in which we implement a nested for-loop using variables as indices:
for i in range(n):
for j in range(n):
acum += values[i][j]
This method takes 42.9 seconds for n=20000, which is very bad.
The main problem here is the use of the i and j variables. Python's dynamic
types and duck typing means that,
at every iteration, the interpreter needs to check...
- ... what the type of
iis - ... what the type of
jis - ... whether
valuesis a list - ... whether
values[i][j]is a valid list entry, and what its type is - ... what the type of
acumis - ... whether
values[i][j]andacumcan be summed and, if so, how - summing two strings is different from summing two integers, which is also different from summing an integer and a float.
All of these checks make Python easy to use, but it also makes it slow. If we want to get a reasonable performance, we need to get rid of as many variables as possible.
Method 2 still uses a nested loop, but now we got rid of the indices and replaced them with list comprehension
for row in values:
for cell in row:
acum += cell
This method takes 17.2 seconds, which is a lot better but still kind of bad.
We have reduced the number of type checks (from 4 to 3), we removed two
unnecesary objects (by getting rid of range), and acum += cell only needs
one type check. Given that we still need checking for cell and row,
we should consider getting rid of them too.
Method 3 and Method 4 are alternatives to using even less variables:
# Method 3
for i in range(n):
acum += sum(values[i])
# Method 4
for row in values:
acum += sum(row)
Method 3 takes 1.31 seconds, and Method 4 pushes it even further with
1.27 seconds. Once again, removing the i variable speed things up,
but it's the "sum" function where the performance gain comes from.
Method 5 replaces the first loop entirely with the map function.
acum = sum(map(lambda x: sum(x), values))
This doesn't really do much, but it's still good: at 1.30 seconds, it is faster than Method 3 (although barely). We also don't have much code left to optimize, which means it's time for the big guns.
NumPy is a Python library for scientific applications. NumPy has a stronger type check (goodbye duck typing!), which makes it not as easy to use as "regular" Python. In exchange, you get to extract a lot of performance out of your hardware.
NumPy is not magic, though. Method 6 replaces the nested list values
defined above with a NumPy array, but uses it in a dumb way.
array_values = np.random.rand(n,n)
for i in range(n):
for j in range(n):
acum += array_values[i][j]
This method takes an astonishing 108 seconds, making it by far the worst performing of all. But fear not! If we make it just slightly smarter, the results will definitely pay off. Take a look at Method 7, which looks a lot like Method 5:
acum = sum(sum(array_values))
This method takes 0.29 seconds, comfortably taking the first place. And even then, Method 8 can do better with even less code:
acum = numpy.sum(array_values)
This brings the code down to 0.16 seconds, which is as good as it gets without any esoteric optimizations.
As a baseline, I've also measured the same code in single-threaded C code. Method 9 implements the naive method:
float **values;
// Initialization of 'values' skipped
for(i=0; i<n; i++)
{
for(j=0; j<n; j++)
{
acum += values[i][j];
}
}
Method 9 takes 0.9 seconds, which the compiler can optimize to 0.4 seconds
if we compile with the -O3 flag (listed in the results as Method 9b).
All of these results are listed in the following table, along with all the
values of n I've tried.
While results can jump a bit depending on circumstances (memory usage,
initialization, etc), I'd say they look fairly stable.
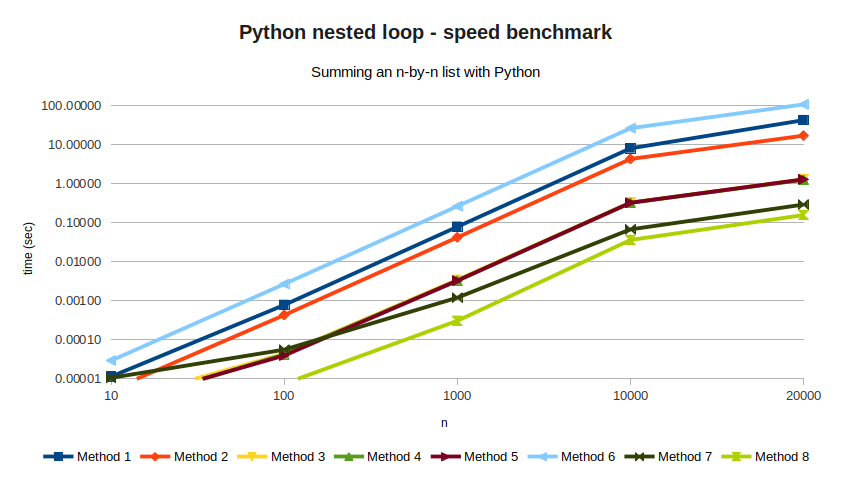
| N=10 | N=100 | N=1000 | N=10000 | N=20000 | |
|---|---|---|---|---|---|
| Method 1 | 0.00001 | 0.00078 | 0.07922 | 8.12818 | 42.96835 |
| Method 2 | 0.00001 | 0.00043 | 0.04230 | 4.34343 | 17.18522 |
| Method 3 | 0.00000 | 0.00004 | 0.00347 | 0.33048 | 1.30787 |
| Method 4 | 0.00000 | 0.00004 | 0.00329 | 0.32733 | 1.27049 |
| Method 5 | 0.00000 | 0.00004 | 0.00329 | 0.32677 | 1.30128 |
| Method 6 | 0.00003 | 0.00269 | 0.26630 | 26.61225 | 108.61357 |
| Method 7 | 0.00001 | 0.00006 | 0.00121 | 0.06803 | 0.29462 |
| Method 8 | 0.00001 | 0.00001 | 0.00031 | 0.03640 | 0.15836 |
| Method 9 | 0.00000 | 0.00011 | 0.00273 | 0.22410 | 0.89991 |
| Method 9b | 0.00000 | 0.00006 | 0.00169 | 0.09978 | 0.40069 |
Final thoughts
I honestly don't know how to convey to Python beginners what the right way to do loops in Python is. With Python being beginner-friendly and Method 1 being the most natural way to write a loop, running into this problem is not a matter of if, but when. And any discussion of Python that includes terms like "type inference" is likely to go poorly with the crowd that needs it the most. I've also seen advice of the type "you have to do it like this because I say so and I'm right" which is technically correct but still unconvincing.
Until I figure that out, I hope at least this short article will be useful for intermediate programmers like me who stare at their blank screen and wonder "two minutes to sum a simple array? There has to be a better way!".
Further reading
If you're a seasoned programmer, Why Python is slow answers the points presented here with a deep dive into what's going on under the hood.
April 21 Update
A couple good points brought up by my friend Baco:
- The results between Methods 3, 4, and 5 are not really statistically significant. I've measured them against each other and the best I got was a marginal statistical difference between Methods 3 and 5, also known as "not worth it".
- Given that they are effectively the same, you should probably go for Method 4, which is the easiest one to read out of those three.
- If you really want to benchmark Python, you should try something more challenging than a simple sum. Matrix multiplication alone will give you different times depending on whether you use liblapack3 or libopenblas as a dependency. Feel free to give it a try!
I need your help liking Rust
If you're a software developer, you know the rules: new year, new programming language. For 2020 I chose Rust because it has a lot going for it:
- Memory safe and high performance
- Designed for low-level tasks
- Backed by Mozilla, of which I'm a fan
- Named "most loved programming language" for the fourth year in a row by the Stack Overflow Annual Survey
With all of these advantages in mind, I set to build something concrete: an implementation of the Aho-Corasick algorithm. This algorithm, at its most basic, builds a Trie and then converts it into an automaton, with the final result being efficient search of sub-strings (why? I hope I can write about why in the near future). It also seemed like the type of problem you'd like to tackle with Rust: implementing a Trie in C requires some liberal use of pointers, a task for which I had expected Rust to be the right tool (memory safety!). And since I need to run a lot of text through it, I need it to be as fast as possible.
So how did I fare? Two weeks into this project, Rust and I have... issues. More specifically, I'm having real trouble figuring out what is Rust good for.
Part I: Pointers and Strings are too complicated
Dealing with pointers is straight up painful, because allocating a piece of
memory and linking it to something else gets very difficult very fast. I
followed this book,
titled "Learn Rust With Entirely Too Many Linked Lists", and the opening alone
warns me that programming a linked list requires learning "the following
pointer types: &, &mut, Box, Rc, Arc, *const, and *mut". A Reddit thread,
on the other hand, suggests that a doubly-linked list is straightforward - all
you need to do is declare your type as Option<Weak<RefCell<Node<T>>>>.
Please note that neither Option, weak, nor RefCell are mentioned in
the previous implementation...
So, pointers are out as killer feature. If optimizing memory usage is not its strong point, then maybe "regular" programming is? Could I do the rest of my text handling with Rust? Sadly, dealing with Strings is not great either. Sure, I get it, Unicode is weird. And I can understand why the difference between characters and graphemes is there. But if the Rust developers thought long and hard about this, why is "get me the first grapheme of this String" so difficult? And why isn't such a common operation part of the standard library?
For the record, this is a rhetorical question - the answer to "how do I iterate over graphemes" (found here) teaches us that...
- ... the developers don't want to commit to a specific method of doing this, because Unicode is complicated and they don't want to have to support it forever. If you want to do it, you have to pick an external library. But it won't be part of the standard library anytime soon. At the same time, ...
- ... they don't want to "play favorites" with any specific library over any other, meaning that no trace of a specific method is to be found in the official documentation.
The result, then, is puzzling: the experts who designed the system don't want to take care of it, the official doc won't tell you who is doing it right (or, more critical, who is doing it wrong and should be avoided), and you are essentially on your own.
Part II: the community
If we've learn anything from the String case, is that "just Google it" is a valid development strategy when dealing with Rust. This leads us inevitably to A sad day for Rust, an event that took place earlier this year and highlighted how bad the Reddit side of the community can be. To quote the previous article,
the Rust subreddit has ~87,000 subscribers (...) while Reddit is not official, and so not linked to by any official resources, it’s still a very large group of people, and so to suggest it’s "not the Rust community" in some way is both true and very not true.
So, why did I bring this up? Because the Reddit thread I mentioned above displays two hallmarks of the type of community I don't want to be a member of:
- the attitude of "it's very simple, all you need to create a new node is
self.last.as_ref().unwrap().borrow().next.as_ref().unwrap().clone()" - the other attitude, where the highest rated comment is the one that includes nice bits like "The only surprising thing about this blog post is that even though it's 2018 and there are many Rust resources available for beginners, people are still try to learn the language by implementing a high-performance pointer chasing trie data-structure". The fact that people may come to Rust because that's the type of projects a systems language is supposedly good for seems to escape them.
If you're a beginner like me, now you know: there is a good community out there. And it would be unfair for me to ignore that other forums, both official and not, are much more welcoming and understanding. But you need to double check.
Part III: minor annoyances
I really, really wish Rust would stop using new terms for concepts that
already exist: abstract methods are "traits", static methods are "associated
functions", "variables" are by default not-variable (and not to be confused with
constants), and any non-trivial data type is actually a struct with
implementation blocks.
And down to the very, very end of the scale, the trailing commas at the end of match expressions, the 4-spaces indentation, and the official endorsement of 1TBS instead of K&R (namely, 4-spaces instead of Tabs) are just plain ugly. Unlike Python, however, Rust does get extra points for allowing other, less-wrong styles.
Part IV: not all is hopeless
Unlike previous rants, I want to point out something very important: I want to like Rust. I'm sure it's very good at something, and I really, really want to find what it is. It would be very sad if the answer to "what is Rust good for?" ended up being "writing Rust compilers".
Now, the official documentation (namely, the book) closes with a tutorial on how to build a multi-threaded web server, which is probably the key point: if Rust claims that error handling and memory safety are its main priorities are true, then multi-threaded code could be the main use case. So there's hope that everything will get easier once I manage to get my strings inside my Trie, and iterating over Gb of text will be amazingly easy.
I'll keep you updated.
