Rust Part II: What is it good for?
Last time I talked about Rust I mentioned that I wanted to like the language but I couldn't find a good reason for using it. Luckily for me, the last Advent of Code gave me the perfect reason for doubling down on Rust, and here's my updated report.
In case you never heard of it, Advent of Code is an online competition that takes place every year in December. It is structured as an Advent calendar where you get a puzzle every day, and where the puzzles get harder and harder every day. Plenty of people use this competition as the perfect excuse for learning a new language, which is how I ended up programming lots of Rust in my spare time.
So here they are: in no particular order, these are the things I like, dislike, and feel mildly uncomfortable about Rust.
Things I like
The one thing I like the most about Rust is the power of the match operator
combined with enums. Unlike in Python, where the implementation of the match
statement is pretty dangerous,
Rust makes it easy to program the type of code that's easy to write, read, and
maintain:
let mut pos = 0;
let mut depth = 0;
for instruction in orders {
match instruction {
Instruction::Forward(meters) => pos += meters,
Instruction::Up(meters) => depth -= meters,
Instruction::Down(meters) => depth += meters,
}
}
Then, there are the compiler errors. While not true for external crates (we'll get to it), compiler errors in Rust are generally helpful, identify the actual source of the problem, and sometimes even give you good suggestions on how to solve the issue. Gone are the days in which a compiler error meant "I know an error happened 50 lines above, but I'll complain about it here instead".
And finally, as someone who has been doing mostly Python for the last years, it feels so good not to have to worry about indentation anymore. This doesn't mean that I'll stop indenting my code - instead, it means that I can finally move a function around without worrying about pasting it one indentation to the left and turning a class into a class and multiple pieces of code that don't compile.
Things I hate
I am puzzled by how aggressively unhelpful arrays are. The puzzle for day 25 could be easily solved (spoilers!) by writing
horizontal_row = horizontal_row>>1 && !(horizontal_row || vertical_row)
but I ended up having to implement it with Vectors of booleans instead. Why?
Because I didn't know how many bits horizontal_row would have at compile time,
and Rust refuses to create arrays with dynamic size.
I am sure there is a way to keep a large binary in memory and manipulate it at
the bit level - otherwise, you wouldn't be able to use Rust for serious game development.
But whatever the method is, it is well hidden.
And on the topic of that puzzle, I come back to one of my main complaints
from last time: popularity is not the correct way to decide which library is
the best one for the job. Do you know the difference between the bitvec,
bit-vec, and bitvector libraries? Can you add either of them to your code
without worrying about the developer going
rogue?
How about the fact that the first result
that comes up for rust bit vector is an accepted StackOverflow answer
suggesting bit-vec... which is no longer maintained?
Minor annoyances
I still can't make sense of the module system. I mean, sure, I know how to put
functionality in sub-directories, but that doesn't really explain why I would
choose between lib.rs, day24.rs, or day24/vm/mod.rs. The
book
could use some improvements on this topic.
If I'm doing something like u16 = u16 + u8 (or even better, u16 += u8),
the compiler should cast the last value automatically.
u8 += u16? Sure, I get it, that's an overflow waiting to happen.
But there is no need for me to get in there and write u16 = u16 + u8 as u16 when we all
know the data fits just fine.
The collect function is very finicky. This is a function that I used quite
often in constructions like .map(|x| something(x)).collect.to_vec(), but more
often than not it will complain about not knowing the type required for collect
even though there is only one type that would make sense.
And since we are talking about the compiler, one of the crates I needed (it was
either nalgebra or ndarray, where I suffered the same problems I had
with bit vectors) had a nasty side effect: if one of your instructions
failed to compile, they all stopped compiling. Good luck finding the one
line that needs fixing!
And finally, I ran a couple times into functionality that had been deprecated in favor of functionality that doesn't currently exist. Not cool.
Conclusion
Would I use Rust again? Yes.
Is it my most loved language? No. But under the right circumstances I could see it happening.
What is it good for? Last time I jokingly said "writing Rust compilers", and I wasn't that far: it's the right programming language for apps that need performance and memory safety, and where we are willing to spend some time calculating who is borrowing from whom in order to get code with fewer bugs. So it's pretty much C++, only with borrowing replacing memory allocations.
I like the idea of giving my original project another try, but I can't make any promises. The Advent of Code has already pushed forward the date of my next project by a couple months, and the time it's taking me to migrate my infrastructure to Ansible is making everything worse.
Unity and Internet-Oriented Software Development
I am developing a simple HTML5 game with Unity. The experience reminded me of my post about Rust and led me to coin a new term that I'd like to discuss today.
Ladies and gentlemen, in the spirit of Object-Oriented Programming I present to you Internet-Oriented Software Development (IOSD): a style of software development in which the official way to program is by trying something, giving up, asking strangers on the internet, and hoping for the best.
You may wonder: how is this new, seeing as that's what we are all already doing? The keyword here is "official". If you want to program with (say) Keras during a long trip with unreliable internet, you could do it with an offline version of the API reference alone. Sure, getting the offline docs will take a bit of work, but at least there's an official repository of knowledge that you can always go to. Of course you can search on the wider internet for help too, but you don't have to.
IOSD is different: when you release IOSD software you publish an okay guide to your software, and that's it. There is no need for you to keep it up to date nor for it to be useful, because your documentation is Internet-Oriented: if someone has a problem, they can ask the internet, IRC channels, their co-workers, anyone but you.
Rust came to mind because, as I complained before, that's how their intended development cycle apparently works: if you don't know how to do something, you are encouraged to either search the forums or ask the developers. In the later case, "we don't know, we won't do it, and we won't tell you who is doing it right" is a possible response. TensorFlow used to be like that too (ask me about the Seq2Seq tutorial!), but they reversed course and their current official suggestion is that you use Keras (no, seriously).
But Unity is an even better example. For starters, the official docs are essentially useless because they tell you what something does but neither why nor what to use it for. Can you guess in which situations is a Sprite renderer required, and what do you need it for? Because I can't. One might argue that Unity Learn is where you should look for answers, in which case one would be wrong. Taking the first course in the "Game development" section, for instance, gets you this tutorial which is only valid for an outdated version of Unity.
No, the real source of answers are YouTube tutorials. Sure, sometimes they refer to windows that aren't there anymore and/or changed their name, but you can always add a "2019.4" to your search and try again.
I am not entirely a beginner with Unity, as I worked with it for my PhD projects. Even then, the list of resources I needed to complete my current project so far includes 5 YouTube tutorials, 2 forum threads, and zero links to official documentation. Is this a problem? Is IOSD better than the thick manuals we had before? Am I the only one getting outdated answers for trivial problems? I have no idea. So I propose a compromise: I will point at the situation and give it a name, let someone else answer the hard questions, and we will share the credit.
Animations in Gephi
Gephi is a tool for graph visualization that's great for plotting big datasets. If you have large, complex graphs to plot, Gephi has plenty of layouts that you can apply to your data and turn a mess of a graph into something that hopefully makes sense.
But there's something Gephi can't do: animations. The layout algorithms at work look awesome, and yet there's no easy way to create a video out of them. Capturing the screen is an alternative, but the final resolution is not really high.
It has been suggested that you could export images of the individual networks at every step and then put them together. Of course, the people who suggested this in the past have also...
- ... sworn that they have scripts to do it,
- ... promised that they'll release them after a quick cleanup, and
- ... disappeared from the internet without having published their solutions.
Therefore, this post.
Note: this post is not an introduction to Gephi, and I'll assume that you know the basics. If you don't know them, these slides look quite good.
Requirements
- Gephi (obviously)
- ImageMagick (to post-process images in bulk)
- FFmpeg (to create the final video)
I am also assuming that you are using Linux. This is not a requirement, but it does make my life easier.
Preparing your data
The first step is to have some data to visualize. For the purposes of this
exercise, you can download this zip file
containing two files named nodes.csv and edges.csv. They form a simple
directed graph that I generated from a sample of directories in my computer.
Now, load them into Gephi:
- Start a new Project
- Load the nodes table:
File → Import spreadsheet → nodes.csv. Follow the steps, but remember to select "Append to existing workspace" in the last one. - Repeat the previous step, this time using the
edges.csvfile.
Next, choose a layout. In my experience it is better to try them all first, see which one gives the best result, and then generate the final graph from scratch. Generating the final graph will take a while, so it's better to do it only once you are sure about which parameters to use.
Exporting all frames
It is now time to run our first script. If you don't have the
Scripting Plugin
installed, you can do it now via Tools → Plugins. We will use it to
write a very simple Python script that does the following:
- Run a single step of a layout
- Take note of the relative size of the graph (we'll come back to this)
- Export it to a PNG file
- Return to step 1.
In case you want to copy-paste it, this is the script I used. Don't forget to remove the comments first, because Gephi doesn't like them.
def make_frames(iters, layout, outdir):
# As many iterations as frames we want to generate
for i in range(iters):
# Run a single step of our layout
runLayout(layout, iters=1)
# Calculate the bounding box of this specific graph
min_x = 0
max_x = 0
min_y = 0
max_y = 0
for node in g.nodes:
min_x = min(min_x, node.x)
max_x = max(max_x, node.x)
min_y = min(min_y, node.y)
max_y = max(max_y, node.y)
width = max_x - min_x
height = max_y - min_y
# Generate a file and include the graph's bounding box
# information in its filename
exportGraph("%s/%05d-%d-%d.png" % (outdir, i, width, height))
Once you have copied this script into the console, you can generate all
animation frames with the command make_frames(100, FruchtermanReingold, "/tmp/").
This will run the FruchtermanReingold layout for 100 iterations, and will save
the generated frames in the /tmp/ directory. Of course, you can choose other
layouts (see the documentation
for more info) and you can run the script for a larger number of steps.
You can also customize the layout parameters in the regular Layout tab, and
the script will pick them up.
The script will block Gephi entirely, so don't go for a really high
number of steps from the beginning. Start with 50-100, and only then move on.
For a nicer effect, make a single run of the "Random" algorithm first.
This will put all your nodes in a very small space, and the final effect will
be like an explosion of nodes.
Generating the animation
A further issue to deal with is the changing size of the image canvas. If we set Gephi to generate a 1024x1024 output image but we only have two nodes close to each other, those two nodes will look huge. If we have thousands of disperse nodes, however, the individual nodes will be barely visible. Therefore, if you made a video with the images we generated in the previous section directly, you would almost certainly get a zoom effect where the nodes would get bigger and smaller as the graph gets denser or sparser respectively.
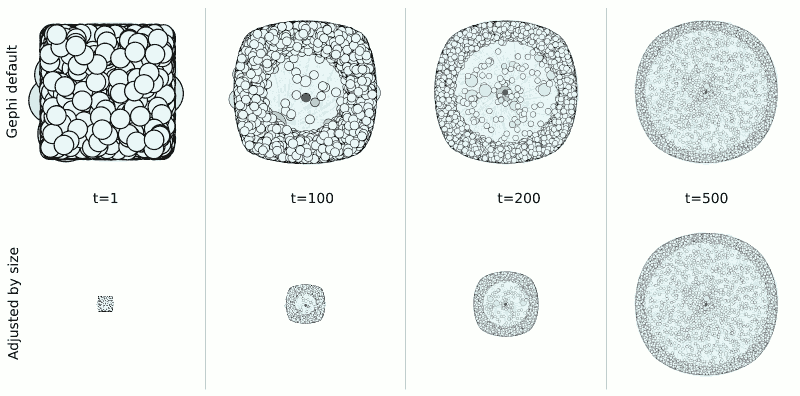
To avoid this, we need to scale all pictures proportionally.
The Bash script below calculates the maximum theoretical size of our graph
(based on those variables we added to the filenames before), scales all images
down to the proper size (as defined by canvas_w and canvas_h), and places
them in the center of a single-color canvas (see the rgb() call).
# Directory where all individual frames are
SOURCE_DIR=/tmp
# Directory where final frames will be stored
TARGET_DIR=/tmp/outdir
# Obtain the theoretical maximum width and height in the PNG frames
max_width=`ls ${SOURCE_DIR}/*png | cut -f 2 -d '-' | sort -n | tail -1`
max_height=`ls ${SOURCE_DIR}/*png | cut -f 3 -d '-' | cut -f 1 -d '.' | sort -n | tail -1`
# Give your desired canvas size
canvas_w=1024
canvas_h=1024
# Scaling factor for the frames, based on the largest theoretical dimension
if (( $max_width > $max_height ))
then
factor=`bc -l <<< "$canvas_w/$max_width"`
else
factor=`bc -l <<< "$canvas_h/$max_height"`
fi
# Generate the new frames
for file in ${SOURCE_DIR}/*png
do
# Obtain the properties of the image
frame=`echo $file | xargs -n 1 basename | cut -f 1 -d '-'`
width=`echo $file | cut -f 2 -d '-'`
height=`echo $file | cut -f 3 -d '-' | cut -f 1 -d '.'`
# Calculate how the image should be scaled down
new_width=`bc -l <<< "scale=0; ($width*$factor)/1"`
new_height=`bc -l <<< "scale=0; ($height*$factor)/1"`
# Put it all together
convert $file -scale ${new_width}x${new_height} png:- | \
convert - -gravity Center -background "rgb(255,255,255)" \
-auto-orient -extent ${canvas_w}x${canvas_h} \
${TARGET_DIR}/${frame}.png
done
Once you have generated this second set of frames, you can generate your final
video going to your TARGET_DIR directory and running the command
ffmpeg -framerate 30 -i %05d.png -c:v libx265 -r 24 final_video.mp4
If your video is too slow, a higher framerate value will do the trick (and
vice versa). The final result, heavily compressed for the internet, can be
seen below:
Final thoughts
I hope you'll find this guide useful. I'm not going to say that it's easy to follow all these steps, but at least you can set them up once and forget about it.
Some final points:
- For an alternative method of graph generation involving nodes with timestamps, this script looks like the way to go.
- I'm interested in unifying everything under a single script - I chose Python because it was easier than Java, but maybe developing a proper multi-platform plugin is the way to go. I can't promise I'll do it, but I'll think about it. In that same vein, perhaps the script should center in a specific node?
- If you plan to publish your video on the internet by yourself, this post gives a nice overview of which standards to use. If you want to tweak the video quality, this SE question provides some magic incantations for FFmpeg.
- Finally, and speaking of magic incantations, special thanks to this post for providing the right ImageMagick parameters.
Wiki idea: what happens when you press Enter on your browser
Here is an idea that I had and that I don't have time to work on. I read somewhere about the following job interview question:
What happens after you write a URL in your browser and press Enter?
If you think about this for a moment, you might realize that what this question really means is "tells us everything you know about computers". I have yet to find a topic that wouldn't be involved in giving a full response. Off the top of my head, and in roughly chronological order, you would have to explain...
- ... how your keyboard sends signals, including the difference between pressing and releasing a key. Also, how your computer display works.
- ... how to turn a series of electric impulses into a character.
- ... how to parse a URL, including the difference between Unicode and ASCII.
- ... how the internet works: DNS, TCP/IP, IPv4 vs IPv6, routing, etc
- ... how the browser and server negotiate the type of content they want. It might also include an introduction to the GZIP compression algorithm.
- ... a primer on HTTPS, including cryptography and handling certificates.
- ... what is a web server and how it works. Same for load balancers, proxies, and pretty much all modern server infrastructure.
- ... how your operating system renders anything on screen.
- ... how your web browser renders content.
- ... the standards involved in receiving content: HTML, CSS, JavaScript, etc.
I imagine that this would be a great idea for a Wiki: the main page would simply present the general question, and you could go deeper and deeper until you reach your motherboard's buses, your microprocessor's cache, the specifics of BGP, or pretty much anything that was ever used in an internet-connected computer.
I was never asked this question, which is a bit of a missed opportunity: I don't know exactly how many hours I could waste on this question, but I'm willing to bet it would be more than what any reasonable interviewer is willing to spend. More realistically, I imagine the point of the question is both to check whether you know about computers and, more important, whether you know when to stop talking about computers.
Recovering Mercurial code from Bitbucket
I received today the type of e-mail that we all know one day will arrive: an e-mail where someone is trying to locate a file that doesn't exist anymore.
The problem is very simple: friends of mine are trying to download code from https://bit.ly/2jIu1Vm to replicate results from an earlier paper, but the link redirects to https://bitbucket.org/villalbamartin/refexp-toolset/src/default/. You may recognize that URL: it belongs to Bitbucket, the company that infamously dropped their support for Mercurial a couple months ago despite being one of the largest Mercurial repositories on the internet.
This is the story of how I searched for that code, and even managed to recover some of it.
Offline backup
Unlike typical stories, several backup copies of this code existed. Like most stories, however, they all suffered terrible fates:
- There was a migration of most of our code to Github, but this specific repo was missed because it belongs to our University group (everyone in that group had access to it) but it was not created under the group account.
- Three physical copies of this code existed. One lived in a hard drive that died, one lived in a hard drive that may be lost, and the third one lives in my hard drive... but it may be missing a couple commits, because I was not part of that project at that time.
At this point my copy is the better one, and it doesn't seem to be that outdated. But could we do better?
Online repositories
My next step was figuring out whether a copy of this repo still exists on the internet - it is well known that everything online is being mirrored all the time, and it was only a question of figuring out who was more likely to have a copy.
My first stop was Archive Team, from the people behind the Internet Archive. This team famously downloaded 245K public repos from Bitbucket, and therefore they were my first choice when checking whether someone still had a copy of our code.
The experience yielded mixed results: accessing the repository with my browser is impossible because the page throws a large number of errors related to Content Security Policy, missing resources, and deprecated attributes. I imagine no one has looked at it in quite some time, as it is to be expected when dealing with historical content. On the command line, however, it mostly works: I can download the content of my repo with a single command:
hg clone --stream https://web.archive.org/web/2id_/https://bitbucket.org/villalbamartin/refexp-toolset
I say "mostly works" because my repo has a problem: it uses sub-repositories, which apparently Archive Team failed to archive. I can download the root directory of my code, but important subdirectories are missing.
My second stop was the Software Heritage archive, an initiative focused on collecting, preserving, and sharing software code in a universal software storage archive. They partnered up with the Mercurial hosting platform Octobus and produced a second mirror of Bitbucket projects, most of which can be nicely accessed via their properly-working web interface. For reasons I don't entirely get this web interface does not show my repo, but luckily for us the website also provides a second, more comprehensive list of archived repositories where I did find a copy.
As expected, this copy suffers from the same sub-repo problem as the other one. But if you are looking for any of the remaining 99% of code that doesn't use subrepos, you can probably stop reading here.
Deeper into the rabbit hole
At this point, we need to bring out the big guns. Seeing as the SH/Octobus repo is already providing me with the raw files they have, I don't think I can get more out of them than what I currently do. The Internet Archive, on the other hand, could still have something of use: if they crawled the entire interface with a web crawler, I may be able to recover my code from there.
The surprisingly-long process goes like this:
first, you go to the Wayback Machine,
give them the repository address, and find the date when the repository was
crawled (you can see it in their calendar view). Then go to the
Kicking the bucket
project page, and search for a date that kind of matches that. In my case
the repository was crawled on July 6, but the raw files I was looking for where
stored in a file titled 20200707003620_2361f623. In order to identify this file I
simply went through all files created on or after July 6, downloaded their
index (in my case, the one named ITEM CDX INDEX) and used zgrep to check
whether the string refexp-toolset (the key part of the repo's name) was
contained in any of them. Once I identified the proper file, downloading the
raw 28.9 Gb WEB ARCHIVE ZST file took about a day.
Once you downloaded this file, you need to decompress it. This file is compressed
with ZST, meaning that you probably
need to install the zstd tool or similar (this one worked in Devuan, so it's
probably available in Ubuntu and Debian too). But we are not done! See, the ZST
standard allows you to use an external dictionary
without which you cannot open the WARC file (you get an Decoding error (36) : Dictionary
mismatch error). The list of all dictionaries is available at the bottom of
this list. How to identify
the correct one? In my case, the file I want to decrypt is called
bitbucket_20200707003620_2361f623.1592864269.megawarc.warc.zst, so the
correct dictionary is the one called archiveteam_bitbucket_dictionary_1592864269.zstdict.zst.
This file has a .zst extension, so don't forget to extract it too!
Once you have extracted the dictionaries, found the correct one, and extracted
the contents of your warc.zst file (unzstd -D <dictionary> <file>) it is now
time to access the file. The Webrecorder
Player didn't work too well
because the dump is too big,
but the warctools package was
helpful enough to realize... that the files I need are not in this dump either.
So that was a waste of time. On the plus side, if you ever need to extract files from the Internet Archive, you now know how.
Final thoughts
So far I seem to have exhausted all possibilities. I imagine that someone somewhere has a copy of Bitbucket's raw data, but I haven't managed to track it down yet. I have opened an issue regarding sub-repo cloning, but I don't expect it to be picked up anytime soon.
The main lesson to take away from here is: backups! I'm not saying you need 24/7 NAS mirroring, but you need something. If we had four copies and three of them failed, that should tell you all you need to know about the fragility of your data.
Second, my hat goes off both to the Internet Archive team and to the collaboration between the Software Heritage archive and Octobus. I personally like the later more because their interface is a lot nicer (and functional) than the Internet Archive, but I also appreciate the possibility of downloading everything and sorting it myself.
And finally, I want to suggest that you avoid Atlassian if you can. Atlassian has the type of business mentality that would warm Oracle's heart if they had one. Yes, I know they bought Trello and it's hard to find a better Kanban board, but remember that Atlassian is the company that, in no particular order,
- regularly inflicts Jira on developers worldwide,
- bought Bitbucket and then gutted it, and
- sold everyone on the promise of local hosting and then discontinued it last week for everyone but their wealthiest clients, forcing everyone else to move to the cloud. Did you know that Australia has legally-mandated encryption backdoors? And do you want to take a guess on where Atlassian's headquarters are? Just saying.
