This is not a secret, but I found it curious and thought about sharing
it here: earlier today I needed to share a video file that I was hosting
in my server, and I decided to send the link over WhatsApp. As I was
looking at the log files at the time, I managed to catch this curious
set of requests:
7c0h.com:443 203.0.113.19 - - [14/Nov/2019:20:02:49 +0100] "GET / HTTP/1.1" 200 5059 "-" "WhatsApp/2.19.305 A"
7c0h.com:443 203.0.113.19 - - [14/Nov/2019:20:02:51 +0100] "GET / HTTP/1.1" 200 1806 "-" "WhatsApp/2.19.305 A"
7c0h.com:443 203.0.113.19 - - [14/Nov/2019:20:02:53 +0100] "GET /fi HTTP/1.1" 404 549 "-" "WhatsApp/2.19.305 A"
7c0h.com:443 203.0.113.19 - - [14/Nov/2019:20:02:53 +0100] "GET /fil HTTP/1.1" 404 688 "-" "WhatsApp/2.19.305 A"
7c0h.com:443 203.0.113.19 - - [14/Nov/2019:20:02:54 +0100] "GET /file HTTP/1.1" 404 689 "-" "WhatsApp/2.19.305 A"
7c0h.com:443 203.0.113.19 - - [14/Nov/2019:20:02:54 +0100] "GET /files HTTP/1.1" 404 690 "-" "WhatsApp/2.19.305 A"
7c0h.com:443 203.0.113.19 - - [14/Nov/2019:20:02:55 +0100] "GET /files3 HTTP/1.1" 404 691 "-" "WhatsApp/2.19.305 A"
7c0h.com:443 203.0.113.19 - - [14/Nov/2019:20:02:57 +0100] "GET /files3.mpr HTTP/1.1" 404 695 "-" "WhatsApp/2.19.305 A"
7c0h.com:443 203.0.113.19 - - [14/Nov/2019:20:03:00 +0100] "GET /files3.mp HTTP/1.1" 404 694 "-" "WhatsApp/2.19.305 A"
7c0h.com:443 203.0.113.19 - - [14/Nov/2019:20:03:01 +0100] "GET /files3.mp4 HTTP/1.1" 200 219785 "-" "WhatsApp/2.19.305 A"
In simple terms: ever since WhatsApp identified that I was sending a
link (that is, after I wrote https://7c0h.com/), WhatsApp generated a
new request for every letter I typed (including the "mpr" typo). It's a
good thing they only downloaded 215Kb of data too, because the request
came straight from my phone. I guess there is no reason to optimize your
code when you don't pay for the bandwidth.
I know this is not in the usual style of this Blog, but I found
something so out of touch with reality in Batgirl
#36 that I
need to share it with you. Please follow me on this journey.
(Warning: spoilers for Batgirl #34–#36. Also, I'm assuming you know
who Batgirl is.)
Our story starts in Batgirl
#34 with
Barbara Gordon (aka Batgirl) missing a meeting with her business partner
Alysia and some of her company's investors due to bat-related
obligations:

As it turns out, the investors are not happy. They bought plenty of
shares in the company, and want to use their position to push Barbara
Gordon out:

Unfortunately for them, they don't have enough shares to kick her out.
Even Alysia tells them so. But they wouldn't be important shareholders
if they didn't have a backup plan, right?

You see: many issues ago, Barbara hired Pamela Isley (aka Poison Ivy,
known eco-terrorist and occasional villain) to develop bee-friendly
plant fertilizer for their company (it's a long story - see "Batgirl and
the Birds of Prey" #12 for details).
The investors have now found out, and want to use this information to
blackmail Alysia into kicking her friend out of the company. If Alysia
does not agree to fire Barbara, they'll make this information public,
tank the company, and put all their employees on the street:

But here's the thing: those investors have acquired a lot of the
company. That is, they own it because they paid for it. Do you know
what would happen to that investment if they went along with their plan?
Yup, you guessed it: gone. All of it. Millions of dollars lost just to
spite one of the company's founders. And it's not like they can sell
their stock either: doing so in this situation is a clear-cut case of
insider trading. Barbara Gordon may end up on the streets, but those
investors would end up in jail.
You would expect a smart executive like Alysia to thank the investors
for their valuable input, promise to call them back, get a good night
sleep, and (at worst) negotiate a good separation agreement for her
friend. A less smart person (but smart nonetheless) would have called
their bluff: Mutually Assured
Destruction
is a good stalling tactic, but only an idiot would actually follow
through.
Of course, none of these perfectly reasonable suggestions occur to
Alysia. She kicks Barbara out of the company instead, leaving her broke
and homeless.
And here is where I draw the line. See, I'm fine with the idea of an
early-20s super-genius with photographic memory jumping from rooftops
and fighting crime without the Police Commisioner noticing that she
looks exactly like his daughter. But now you want me to believe that
executives from a million-dollar company wouldn't have the simplest
grasp of economy? Hell, do you want me to believe that you can organize
a hostile takeover, fire a company founder, and freeze their assets in
less than 3 hours?! Talk about nonsense.
With that out of the way, and as a final point, I would like to call
your attention to Alysia's last words to Barbara. I think you'll agree
that her frustration is a little... misplaced.

No, Alysia, Barbara isn't letting "them" take away her life's work. That
one's entirely on you.
This post is a condensed version of a talk I gave at my research
group.
I've been lucky enough to attend both EMNLP
2018 and INLG 2018,
and I thought it would be useful to share my main impressions of which
cool things happened during the conference. I've split them into four
sections: General tendencies about the direction that modern NLG
research is taking, Practical considerations to be aware of for your
own daily research, Exciting research areas where interesting results
are being produced, and Fun ideas that I stumbled upon while walking
around.
General tendencies
For me, one of the most important aspects of going to conferences is
getting a sense of what has changed and what is coming. In that spirit,
this conference season taught me that...
It is now okay to make a presentation full of memes: Are you leading
a half-day tutorial for over 1K researchers? Put some minions on your
slides, it's cool.
The text produced by neural networks is fine: For the last years,
computational linguists have been worrying that, while neural networks
produce text that looks okay-ish, it is still far from natural. This
year we have finally decided not to worry about this anymore. Or, as
described in Yoav Goldberg's
slides,
"Yay it looks readable!".
BLEU is bad: It is not every day that you see presenters apologizing
for the metric they've used in their paper. It's even less common when
they do it unprompted, and yet here we are. BLEU is a poor fit for
modern NLG tasks, and yet everyone is still waiting for someone to come
up with something better.
Further reading: BLEU is not suitable for the evaluation of text
simplification, and ChatEval: A
tool for the systematic evaluation of Chatbots
for a human-evaluation platform.
Need something done? Templates are your friends: We are all having a
lot of fun with Neural this and Deep that. The companies that are
actually using NLP, though? Templates, all of them. So don't discount
them yet.
Further reading: Learning Neural Templates for text
generation.
Practical considerations
Classical NLP is still cool, as long as you call it anything else:
Everyone knows that real scientists train end-to-end neural networks.
But did you know that tweaking your data just a bit is still fine? All
you have to do is pick one of the many principles that the NLP community
developed in the last 50+ years, call it something else, and you're
done.
Further reading: Handling rare items in data-to-text
generation.
Be up to date in your embeddings: It is now widely accepted that you
should know what fastText and Glove embeddings are. And ELMO and BERT
are here to stay too. So if you're not up to date with those (or, at the
very least, my post on
Word2Vec),
then it's time to start reading.
Further reading: want to use fastText, but at a fraction of the cost?
Generalizing word embeddings using bag of
subwords.
Data is a problem, and transfer learning is here to help: Transfer
Learning is a technique in which you take a previously-trained model and
tweak it to work on something else. Seeing as how difficult it is to
collect data for specific domains, starting from a simpler domain may be
more feasible that training everything end-to-end yourself.
Exciting research areas
If you are working on NLG, which I do, then you might be interested in a
couple specific research directions:
Understanding what neural networks do: This topic has been going on
for a couple years, and shows no end in sight. With neural methods
everywhere, it only makes sense to try and understand what is it exactly
that our morels are learning.
Further reading: Want to take a look at the kind of nonsense that a
neural network might do? Pathologies of Neural Models Make
Interpretations Difficult.
Copy Networks and Coverage: The concepts of Copy Networks (a neural
network that can choose between generating a new word or copying one
from the input) and Coverage (mark which sections of the input have
already been used) where very well put together in a summarization paper
titled "Get to the point! Summarization with Pointer-Generator
Networks. Those
techniques are still being explored, and everyone working on
summarization should be at least familiar with them.
Further reading: On the abstractiveness of Neural Document
Summarization explores what are
copy networks actually doing.
AMR Generation is coming: Abstract Meaning Representation (AMR) is a
type of parsing in which we obtain formal representations of the meaning
of a sentence. No one has managed yet to successfully parse an entire
document (as far as I know), but once it's done the following steps are
mostly obvious: obtain the main nodes on the text, feed them to a neural
network, and obtain a summary of your document. Work on this has already
began, and I look forward to it.
Further reading: Guided Neural Language Generation for Abstractive
Summarization using AMR.
Fun ideas
I don't want to finish this post without including a couple extra papers
that caught my eye:
My relation with Taylor Swift is complicated: I don't hate her
— in fact, she seems like a very nice person. But I definitely hate her
songs: her public persona always comes up to me as entitled, abusive, and/or an
unpleasant person overall. But what if she didn't have to be? What if we could
take her songs and make them more polite? What would that be like?
In today's post we will use the power of science to answer this question.
In particular, the power of Natural Language Processing (NLP) and word
embeddings.
The first step is deciding on a way to model songs. We will reach into our
NLP toolbox and take out
Distributional
semantics, a research area that
investigates whether words that show up in similar contexts also have similar
meanings. This research introduced the idea that once you treat a word like a
number (a vector, to be precise, called the embedding of the word), you
can apply regular math operations to it and obtain results that make sense.
The classical example is a result shown in
this paper, where
Mikolov and his team managed to represent words in such a way that the
result of the operation King - man + woman ended up being very
close to Queen.
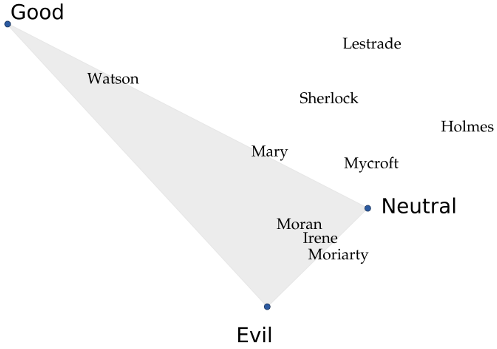
The picture below shows an example. If we apply this technique to all the
Sherlock Holmes novels, we can see that the names of the main characters are
placed in a way that intuitively makes sense if you also plot the locations for
"good", "neutral", and "evil" as I've done.
Mycroft, Sherlock Holmes' brother,
barely cares about anything and therefore is neutral; Sherlock, on the other hand,
is much "gooder" than his brother. Watson and his wife Mary are the least
morally-corrupt characters, while the criminals end up together in their own
corner. "Holmes" is an interesting case: the few sentences where people
refer to the detective by saying just "Sherlock" are friendly scenes, while the
scenes where they call him "Mr. Holmes" are usually tense, serious, or may even
refer to his brother. As a result, the world "Sherlock" ends up with a positive
connotation that "Holmes" doesn't have.
This technique is implemented by
word2vec, a series of
models that receive documents as input and turn their words into vectors.
For this project, I've chosen the
gensim Python library. This
library does not only implement word2vec but also
doc2vec, a model that will do all the heavy-lifting for us when it
comes to turn a list of words into a song.
This model needs data to be trained, and here our choices are a bit limited.
The biggest corpus of publicly available lyrics right now is (probably) the
musiXmatch Dataset,
a dataset containing information for 327K+ songs. Unfortunately, and thanks to
copyright laws, working with this dataset is complicated. Therefore, our next
best bet is this corpus
of 55K+ songs in English, which is much easier to get and work with.
The next steps are more or less standard: for each song we take their words,
convert them into vectors, and define a "song" as a special word whose meaning
is a combination of its individual words. But once we have that, we can start
performing some tests. The following code does all of this, and then asks an
important question: what would happen if we took Aerosmith's song
Amazing,
removed the amazing part, and chose the song that's most similar
to the result?
import csv
import gzip
from gensim.models import Doc2Vec
from gensim.models.doc2vec import TaggedDocument
documents = []
with gzip.open('songlyrics.zip', 'r') as f:
csv_reader = csv.DictReader(f)
counter = 0
# Read the lyrics, turn them into documents,
# and pre-process the words
for row in csv_reader:
words = simple_preprocess(row['text'])
doc = TaggedDocument(words, ['SONG_{}'.format(counter)})
documents.append(doc)
counter += 1
# Train a Doc2Vec model
model = Doc2Vec(documents, size=150, window=10, min_count=2, workers=10)
model.train(document, total_examples=len(documents), epochs=10)
# Apply some simple math to a song, and obtain a list of the 10
# most similar songs to the result.
# In our lyrics database, song 22993 is "Amazing", by Aerosmith
song = model['SONG_22993']
query_vector = song - model['amazing']
for song, vector in model.docvecs.most_similar([query_vector]):
print(song)
One would expect that Amazing minus amazing
would be... well, boring. And you would be right! Predictably,
when we do exactly that we end up with...
- ...Margarita,
a song about a man who meets a woman in a bar and cooks soup with her.
- ...Alligator,
a song about an alligator lying by the river.
- ...Pony Express,
a song about a mailman delivering mail.
We can use this same model to answer all kind of important questions I didn't
know I had:
- Have you ever wondered what would be "amazingly lame"? I can tell you!
Amazing + lame =
History
in the making, a song where a rapper tells us how much money he has.
- Don't you think sometimes "I like
We
are the World, but I wish it had more
violence?". If so,
Blood
on the World's hands is the song for you.
- What if we take Roxette's
You
don't understand me and add understanding to
it? As it turns out, we end up with
It's you,
a song where a man breaks up with his wife/girlfriend because he can't be the
man she's looking for. I guess he does understand her now but still: dude, harsh.
- On the topic of hypotheticals: if we take John Lennon's
Imagine
and we take away the imagination, all that's left is George
Gershwin's
Strike up
the band, a song about nothing but having "fun, fun, fun". On the other
hand, if we added even more imagination we end up with
Just
my imagination, dreaming all day of a person who doesn't even know us.
This is all very nice, but what about our original question: what if
we took Taylor Swift's songs and removed all the meanness? We can start with
her Grammy-winning songs, and the results are actually amazing: the song that
best captures the essence of
Mean
minus the meanness is
Blues
is my middle name, going from a song where a woman swears vengeance to
a song where a man quietly laments his life and hopes that one day things will
come his way.
Adding politeness to
We are never coming back together results in
Everybody
knows, a song where a man lets a woman know he's breaking up with her in a
very calm and poetic way. The change is even more apparent when the bitter
Christmases
when you were mine turns into the (slightly too) sweet memories of Christmas
brought by
Something
about December.
Finally, and on the other side,
White
Horse works better with the anger in. While this song
is about a woman enraged at a man who let her down, taking the meanness out
results in the hopeless laments of
Yesterday's Hymn.
So there you have it. I hope it's clear that these are completely accurate
results, that everything I've done here is perfectly scientific, and that any
kind of criticism from Ms. Swift's fans can be safely disregarded.
But on a more serious note: I hope it's clear that this is only the tip of the
iceberg, and that you can take the ideas I've presented here in many
cool directions. Need a hand? Let me know!
Further reading
